yolov11官方框架:https://github.com/ultralytics/ultralytics
【算法介绍】
在C++中使用纯OpenCV部署YOLOv11进行目标检测是一项具有挑战性的任务,因为YOLOv11通常是用PyTorch等深度学习框架实现的,而OpenCV本身并不直接支持加载和运行PyTorch模型。然而,你可以通过一些间接的方法来实现这一目标,比如将PyTorch模型转换为ONNX格式,然后使用OpenCV的DNN模块加载ONNX模型。
以下是一个大致的步骤指南,用于在C++中使用OpenCV部署YOLOv11(假设你已经有了YOLOv11的ONNX模型):
- 安装依赖:
- 确保你的开发环境已经安装了OpenCV 4.x(带有DNN模块)和必要的C++编译器。
- 准备模型:
- 将YOLOv11模型从PyTorch转换为ONNX格式。这通常涉及使用PyTorch的
torch.onnx.export函数。 - 确保你有YOLOv11的ONNX模型文件、配置文件(描述模型架构)和类别名称文件。
- 将YOLOv11模型从PyTorch转换为ONNX格式。这通常涉及使用PyTorch的
- 编写C++代码:
- 使用OpenCV的DNN模块加载ONNX模型。
- 预处理输入图像(如调整大小、归一化等),以符合模型的输入要求。
- 将预处理后的图像输入到模型中,并获取检测结果。
- 对检测结果进行后处理,包括解析输出、应用非极大值抑制(NMS)和绘制边界框。
- 编译和运行:
- 使用C++编译器(如g++)编译你的代码。
- 运行编译后的程序,输入图像或视频,并观察目标检测结果。
需要注意的是,由于YOLOv11是一个复杂的模型,其输出可能包含多个层的信息(如特征图、置信度、边界框坐标等),因此你需要仔细解析模型输出,并根据YOLOv11的具体实现进行后处理。
此外,由于OpenCV的DNN模块对ONNX的支持可能有限,某些YOLOv11的特性(如自定义层、特定的激活函数等)可能无法在OpenCV中直接实现。在这种情况下,你可能需要寻找替代方案,如使用其他深度学习库(如TensorRT、ONNX Runtime等)来加载和运行模型,并通过C++接口与这些库进行交互。
总之,在C++中使用纯OpenCV部署YOLOv11是一项具有挑战性的任务,需要深入理解YOLOv11的模型架构、OpenCV的DNN模块以及ONNX格式。如果你不熟悉这些领域,可能需要花费更多的时间和精力来学习和解决问题。
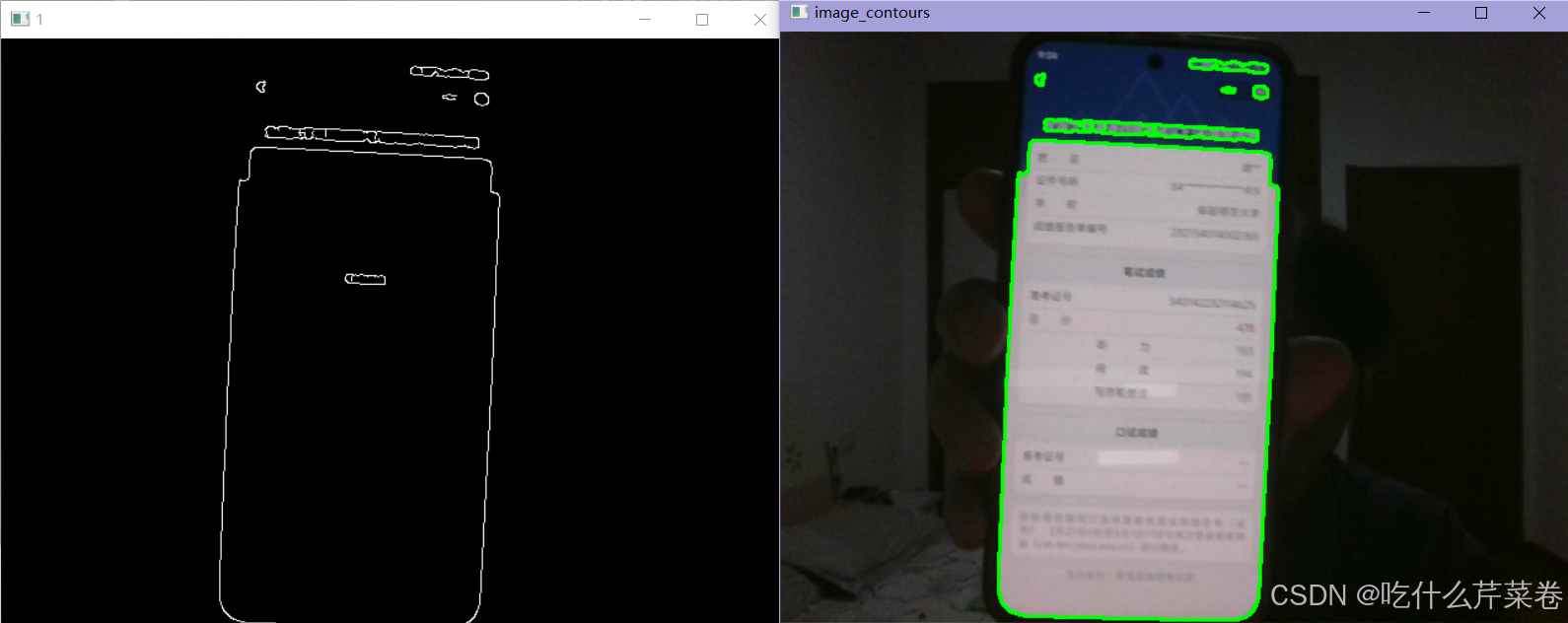
【效果展示】

【测试环境】
vs2019
cmake==3.24.3
opencv==4.8.0
【部分实现代码】
#include <iostream>
#include<opencv2/opencv.hpp>
#include<math.h>
#include "yolov11.h"
#include<time.h>
#define VIDEO_OPENCV //if define, use opencv for video.
using namespace std;
using namespace cv;
using namespace dnn;
template<typename _Tp>
int yolov11(_Tp& cls,Mat& img,string& model_path)
{
Net net;
if (cls.ReadModel(net, model_path, false)) {
cout << "read net ok!" << endl;
}
else {
return -1;
}
//生成随机颜色
vector<Scalar> color;
srand(time(0));
for (int i = 0; i < 80; i++) {
int b = rand() % 256;
int g = rand() % 256;
int r = rand() % 256;
color.push_back(Scalar(b, g, r));
}
vector<OutputSeg> result;
if (cls.Detect(img, net, result)) {
DrawPred(img, result, cls._className, color);
}
else {
cout << "Detect Failed!" << endl;
}
system("pause");
return 0;
}
template<typename _Tp>
int video_demo(_Tp& cls, string& model_path)
{
vector<Scalar> color;
srand(time(0));
for (int i = 0; i < 80; i++) {
int b = rand() % 256;
int g = rand() % 256;
int r = rand() % 256;
color.push_back(Scalar(b, g, r));
}
vector<OutputSeg> result;
cv::VideoCapture cap("D:\\car.mp4");
if (!cap.isOpened())
{
std::cout << "open capture failured!" << std::endl;
return -1;
}
Mat frame;
#ifdef VIDEO_OPENCV
Net net;
if (cls.ReadModel(net, model_path, true)) {
cout << "read net ok!" << endl;
}
else {
cout << "read net failured!" << endl;
return -1;
}
#else
if (cls.ReadModel(model_path, true)) {
cout << "read net ok!" << endl;
}
else {
cout << "read net failured!" << endl;
return -1;
}
#endif
while (true)
{
cap.read(frame);
if (frame.empty())
{
std::cout << "read to end" << std::endl;
break;
}
result.clear();
#ifdef VIDEO_OPENCV
if (cls.Detect(frame, net, result)) {
DrawPred(frame, result, cls._className, color, true);
}
#else
if (cls.OnnxDetect(frame, result)) {
DrawPred(frame, result, cls._className, color, true);
}
#endif
int k = waitKey(10);
if (k == 27) { //esc
break;
}
}
cap.release();
system("pause");
return 0;
}
int main() {
string detect_model_path = "./yolo11n.onnx";
Yolov11 detector;
video_demo(detector, detect_model_path);
}
【视频演示】
C++使用纯opencv部署yolov11目标检测onnx模型演示源码+模型_哔哩哔哩_bilibili【测试环境】vs2019cmake==3.24.3opencv==4.8.0更多实现细节和源码下载参考博文https://blog.csdn.net/FL1623863129/article/details/142688868, 视频播放量 1、弹幕量 0、点赞数 0、投硬币枚数 0、收藏人数 0、转发人数 0, 视频作者 未来自主研究中心, 作者简介 未来自主研究中心,相关视频:用C#部署yolov8的tensorrt模型进行目标检测winform最快检测速度,将yolov5-6.2封装成一个类几行代码完成语义分割任务,C++使用纯opencv去部署yolov8官方obb旋转框检测,使用C#的winform部署yolov8的onnx实例分割模型,超变态的AI换脸工具,解除限制!解锁高级功能!,YOLOv8检测界面-PyQt5实现,基于onnx模型加密与解密深度学习模型保护方法介绍,基于opencv封装易语言读写视频操作模块支持视频读取和写出,使用易语言调用opencv进行视频和摄像头每一帧处理,使用纯opencv部署yolov5目标检测模型onnx![]() https://www.bilibili.com/video/BV1Nc4LekE1d/
https://www.bilibili.com/video/BV1Nc4LekE1d/
【源码下载】
https://download.csdn.net/download/FL1623863129/89837170